
摘要: 少数民族文学不仅是中华民族的财富,更是全人类的财富。近些年来,学界对少数民族文学作品对外传播给予高度关注,将大量经典的少数民族文学作品翻译成各种语言向世界宣扬中华优秀文化。但针对少数民族文学作品对外传播成效的相关研究较少,如果能及时了解读者反馈并及时更新翻译策略和传播方式,能更好提升传播效果。拟介绍如何通过网络爬虫分析西方主要购书网站和书评网站针对相关少数民族文学作品的评论数据,并对这些评论数据进行数据挖掘和情感分析,以期找到少数民族文学对外传播中的经验和存在的问题。
关键词: 传播成效; 网络爬虫; 少数民族文学
1 .背景和现状
1.1 研究背景和意义
美国学者 H·拉斯维尔在《传播在社会中的结构与功能》一文中,提出了构成传播过程的五种基本要素,形成了后来人们称之“五W 模式”过程模式。这五个W 分别是英语中五个疑问代词的第一个字母,即: Who (谁) 、Says What ( 说了什么) 、In Which Channel ( 通过什么渠道) 、To Whom (向谁说) 、With What Effect ( 有什么效果) 。目前为止,对少数民族文学对外传播的研究,往往只注重前面两个 W,也就是注重选择经典的少数民族文学作品( Who) ,然后花大力气将其翻译后对外传播( Says What) 。对后面的三个W( In Which Channel,To Whom,With What Effect)也就是通过何种渠道何种方式对外传播,对不同地区、不同文化背景和不同宗教背景是否选择合适的传播途径和传播形式,尤其是传播效果如何等等这些研究都关注较少。
目前大家更重视选择少数民族文学作品和注重少数民族文学翻译过程,但是作品在翻译完成后是否达到预定的传播效果,这方面的研究鲜有所见。如果不了解受众的反馈信息就会导致自说自话,达不到预定的目的也无从改进,因此关于受众信息反馈需要进一步深入研究。
本文拟通过网络爬虫收集西方主要购书网站和书评网站针对相关少数民族文学作品的评论数据,并对这些评论数据进行数据挖掘和情感分析,以期找到少数民族文学对外传播中的经验和存在的问题。
1. 2 问题研究现状
关于“少数民族文学”外译相关研究: 魏清光教授指出少数民族文学作品对外翻译的必要性: 少数民族文学作品更能代表中国的传统价值观,能够向世界传递中国和平发展的意愿和能力。同时魏教授为如何系统的输出少数民族典籍从多个方面进行了规划。通过魏教授研究我们可以知道少数民族文学对外传播重点在功能路径上,虽然向与中国关系不好的国家传播中华文化难度较大,但如果能有效对向外译介中国典籍文化可以起到缓和矛盾、冲突、误解等的文化功能作用。魏教授这一研究也为本项目明确数据调查对象指明了方向,就是少数民族典籍对外传播的主要对象是目前跟我们国家关系不太好但又在国际有影响力的大国. 比如印度,印度是我们国家的重要邻居,但也对我们国家充满的敌意,如果能够顺利推动少数民族经典作品向印度普通民众推广,传递中华民族和平发展、互利共赢的理念对增进彼此相互了解和沟通,从而对两国和平共处起到促进作用。
魏清光教授等明确指出少数民族文学对外译介存在“输出渠道单一、输出效能不理想”的问题。从该文献可以知道,目前我们的少数民族文学对外译介大多都依赖出版渠道,通过书籍的方式传播,这种形式过于单一不便于推广。曾路指出少数民族文化对外传播方面除了使用传统的媒体外,也应该通过新媒体技术“网络,数字化视频、音频媒介系统,手机信息服务,桌面视窗、触摸媒介”促进少数民族文化对外传播. 随着科技的进步,尤其是互联网的发展,新媒体强势崛起的背景下找到受众国家民众普遍使用且接受的传播形式正是本项目重点解决的问题之一
李敏杰通过模因理论得出了民族典籍外译经历同化、记忆、表达和传播四个阶段. 同时李教授根据模因理论指出少数民族文学作品对外译介要注重“研究西方读者的接受心理和阅读趣味,了解他们的思想价值观念、读译作的目的、对译作的评价等”,他同时指出只有译者做到“知己知彼”,才能使自己的译作被他文化中的读者所接受。从李教授的研究可以得知,通过一定的方式收集和分析国外读者态度和评价、意见和建议对有效推动少数民族典籍对外传播非常必要。
关于网络爬虫相关研究: 网络爬虫又称网络蜘蛛,是指按照某种规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常包含其他网页的入口,网络爬虫则通过一个网址依次进入其他网址获取所需内容。通过网络爬虫分析网络数据的相关研究非常多,例如通过Python 编写爬虫获取微博评论,以此发现舆情演变规律和潜在风险,为舆情引导提供决策支持。随着移动互联网的发展和普及,如何在移动互联网环境下获取数据也是网络爬虫新的研究领域。介绍了一种系统将网络爬虫技术和数据分析以及 Android 相结合起来并利用现有的技术设计一种校园舆情分析的系统。
2 关键技术介绍
2. 1 基于 Python 网络爬虫介绍
Python 是一种开发语言,在人工智能、数据分析、网络爬虫等领域具有其他现有语言不可替代的优势。基于 Python的网络爬虫由调度器、URL管理器、下载器、网页解析器、应用程序五个部分组成,具体如图 1 所示。调度器是爬虫程序的中枢系统,主要负责其他四个部分的工作; URL管理器包括所有的URL地址,包括已经爬取的地址和未爬取的地址便于调度器管理哪些地址已经爬取; 网页下载器是下载未爬取的URL地址网页,在 Python 中的 urllib2 已经实现网页下载器的部分功能; 网页解析器首先网页下载器下载后得到的网页字符串进行解析,用户可以根据需求提取出相关信息; 各种应用是指从网页中提取的用户想要数据的应用程序。
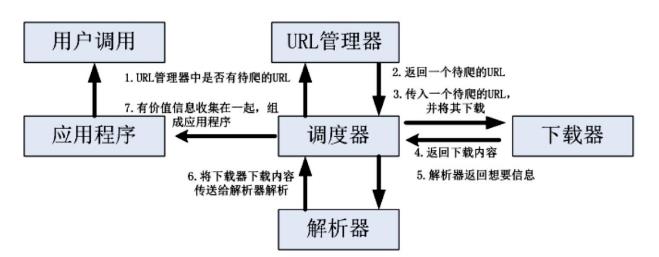
图 1 基于 Python 的网络爬虫总体框架
2. 2 核心软件及其功能介绍
Scrapy 是一个应用程序框架,可以实现遍历爬行网站、分解获取数据。其应用非常广泛,诸如数据挖掘、信息处理等等,具体如图 2 所示。
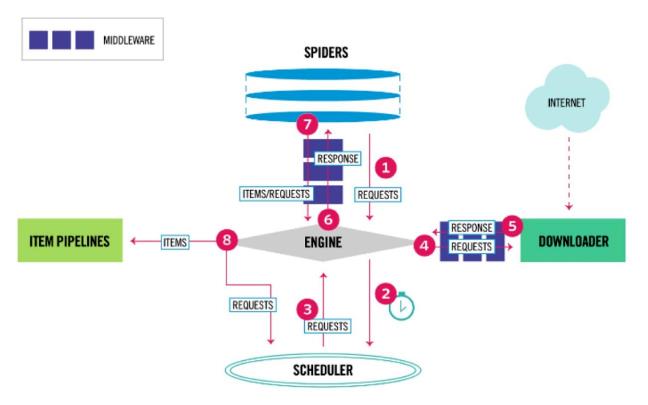
图 2 Scrapy 架构图
Scrapy 执行过程由执行引擎完成控制,具体过程如下:
①引擎从 Spiders 中获取到最初的要爬取的请求;
②引擎安排请求到调度器中,并向调度器请求下一个要爬取的请求;
③调度器返回下一个要爬取的请求给引擎;
④引擎将上步中得到的请求通过下载器中间件发送给下载器,这个过程中下载器中间件中的process_request( ) 函数会被调用到;
⑤上一步完成后,下载器生成一个该页面的 Re- sponse,并将 Response 通过下载中间件调用 process_ response( ) 函数,将 Response 传送给引擎;
⑥引擎得到Response 后,通过 Spider中间件调用process_spider_input( ) 函数发送给 Spider 处理;
⑦Spider 处理 Response 请求,完成后通过 Spider中间件返回爬取到 Item 及新的请求给引擎;
⑧引擎将上步中 Spider 爬取到的 Item 给管道,将 Spider 处理的请求发送给调度器,并向调度器请求可能存在的下一个要爬取的请求;
⑨重复执行直到调度器中没有更多的请求.
区别于静态数据,由于本文中涉及到的网络留言是动态数据,需要找到一种工具能收集动态页面数据,Selenium 就是其中较为杰出代表。Selenium 是一个基于浏览器的自动化工具,它提供了一种跨平台、跨浏览器的端到端的 web 自动化解决方案。Sele- nium 测试直接运行在浏览器中,就像真正的用户在操作一样,可以模拟浏览器进行网页加载,网络爬虫工具下使用 Selenium 针对动态页面非常有效。
在完成数据收集后,对数据有效分析也是关键问题之一。本文中收集到的数据可以依靠Pandas工具,pandas是基于 NumPy的一种工具,Pandas纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具. pandas 提供了大量能快速便捷地处理数据的函数和方法。正是由于 pandas 的存在,才能使 Python 成为强大而高效的数据分析环境的重要因素之一,本文可以使用 Pandas 对网络爬虫收集到的数据进行进一步分析和处理。
在完成数据收集和分析之后,需要对数据进行进一步挖掘,例如本文中的评论数据,如何判断该评论是正面还是负面,抑或是中性? 需要对收集到的文本进行情感计算。又由于本文所收集的文本以英文为主,本文中使用 Python 中的 TextBlob 工具,该工具可以为本文在文本挖掘和分析上提供支撑。TextBlob工具是一个用 Python 编写的开源的文本处理库. 它可以用来执行诸多自然语言尤其是英语的处理任务。比如英文词性标注,英文名词性成分的提取,英文文本情感的分析,英文文本翻译等等强大功能
本文中使用 TextBlob 对英文进行简单情感分析,以此来判断读者对翻译文献的评价和态度。
TextBlob 主要针对英文,如果要分析中文文本可以使用 SnowNLP 工具. 该工具与 TextBlob 类似,方便处理中文文本的情感分析。
3. 主要实施流程
在本节中,我们将详细介绍实验平台搭建方案和具体实现流程. 为下一步具体实施奠定基础。由于亚马逊评论详情页是动态加载,本文拟通 seleninum 进行模拟用户行为,爬取,然后用 pandas 写入 csv 文件,解决乱码和无序问题。
3. 1 环境搭建
操作系统: Windows10.
开发环境:PyCharm Community Edition.
开发语言: Python2.7、pip 工具
浏览器软件: Firefox 浏览器( 版本 55.0 ) 以及Firefox 插件 FirePath.
其他工具: selenium 3.7.0,scrapy 1.4.0,并通过pip 工具在 scrapy 环境中安装 selenium.
3. 2 数据采集
3.2.1 获取目标网址
首先定位到需要分析的书所在网页,例如亚马逊网站中著名藏族文学家阿来创作的《格萨尔王传》,由著名汉学家葛浩文翻译的英文版《The Song of King Gesar》。由于加载评论的页面被封装起来,可以使用浏览器开发者工具获取保存评论的页面,然后用正则表达式获取有效数据内容,去除无用部分。
3.2.2 爬虫框架的选用
选择 python 的 scrapy 模块爬取,同时需要加载上selenium 工具. 具体步骤可以参考 2.2 节所示。
3.3 数据处理
3.3.1 数据存储
将爬虫收集到的数据存储于数据库对后面的数据分析和挖掘非常关键,由于本文中采集的数据量较少,数据库可以选用 mysql。
3.3.2 数据清洗
由于网络爬虫收集到各种各样数据,并不一定是想要的,在此步骤需要通过正则表达式将数据进行清理,删除无效数据,确保后面数据分析和数据挖掘的准确性。
3.3.3 数据初步分析
在完成上述步骤后,利用 TextBlob 对真实用户文本数据进行挖掘,初步判断用户对待各种作品的态度和评价。
4.总结
本文将少数民族文学作品外译过程中用户态度和评价作为研究目标。拟通过网络爬虫对国外主要购书网站和书评网站相关的评论数据进行收集,然后对数据进行处理后进一步挖掘和情感分析,以期找到少数民族文学对外传播中的经验和存在的问题。本文以亚马逊网站为例,针对其特点重点介绍该类网站的网络爬虫框架和具体实施步骤,下一步将对具体细节进一步完善,将收集到的数据分析整理后,为少数民族文学作品对外译介过程提供有价值的建议。
作者简介
张敏 ,男,汉族,实验师,博士,西南民族大学讲师,研究方向: 信息安全、网络爬虫及数据分析。
李野,西南民族大学中国语言文学学院2019级博士生,外国语言文学学院助理研究员,研究方向:少数民族文学与文化对外传播、比较文学与世界文学。
原文刊于《西南民族大学学报( 自然科学版)》,2019年3 月第 45 卷第 2期。 注释从略,详见原刊。
凡因学术公益活动转载本网文章,请自觉注明
“转引自中国民族文学网(http://iel.cass.cn)”。